Kaggle / Titanic - Machine Learning from Disaster / 独学 / とりあえず自分でやってみる Day4
環境
Jupyter Lab / Local
今日やったこと
以前に下記の棒グラフを出力して眺めていた時に、
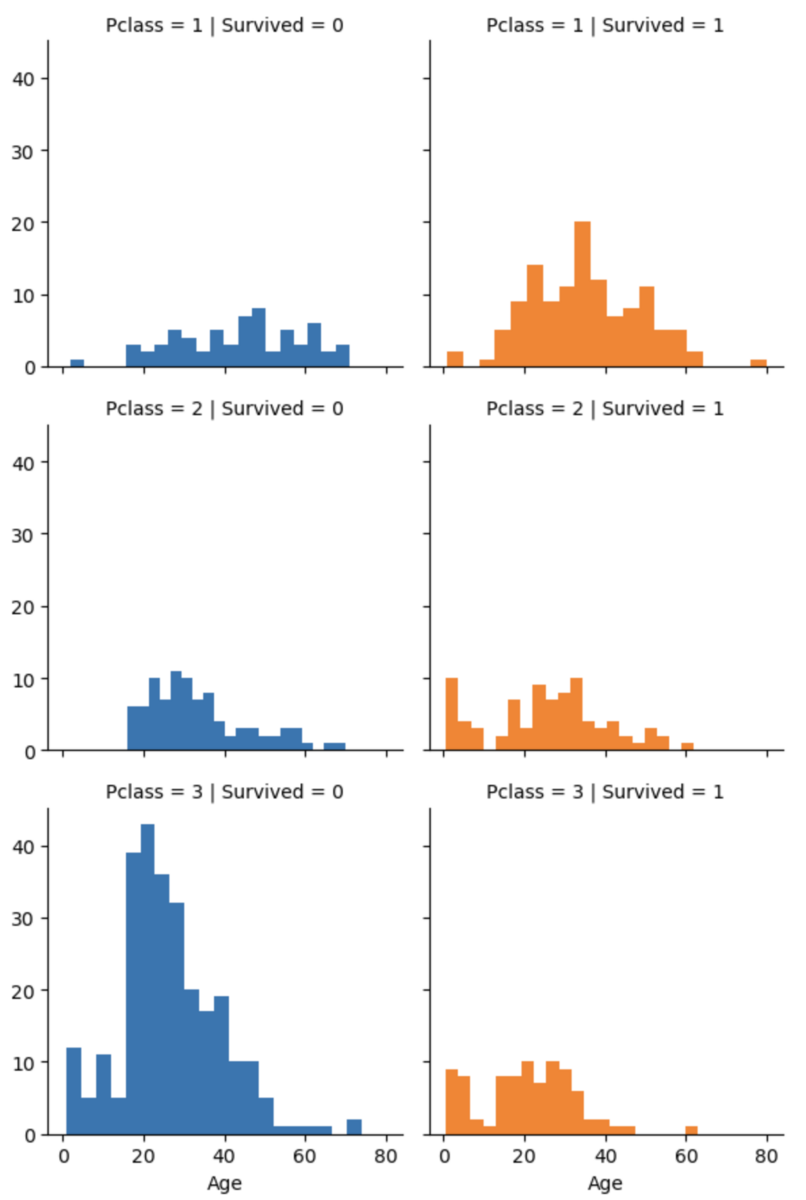 子どもの中でも特に幼児は生存率が極めて高いなと思っていました。'Pclass'が3, すなわち階級が低い層ではそんなことのない「北斗の拳」的世界観でしたが、それ以外では傾向が強いなと。まずは'Pclass'は置いておいて全体で幼児を切り分けて特徴量にしようと思いました。
子どもの中でも特に幼児は生存率が極めて高いなと思っていました。'Pclass'が3, すなわち階級が低い層ではそんなことのない「北斗の拳」的世界観でしたが、それ以外では傾向が強いなと。まずは'Pclass'は置いておいて全体で幼児を切り分けて特徴量にしようと思いました。
'Age'が連続数値型だったので'AgeBand'として年齢幅のカテゴリ化。
train_df_drpd['AgeBand'] = pd.cut(train_df_drpd['Age'], 12) train_df_drpd[['AgeBand', 'Survived']].groupby(['AgeBand'], as_index=False).mean().sort_values(by='AgeBand', ascending=True)
pandasの.cut()のパラメーターを色々と変えて
 'Survived'との相関係数が最も高くなる閾値を見ます。Jupyter LabなのでパラメーターいじってはShit+Enterの繰り返しで7歳未満で区切ると0.7以上が出ることが分かりました。
'Survived'との相関係数が最も高くなる閾値を見ます。Jupyter LabなのでパラメーターいじってはShit+Enterの繰り返しで7歳未満で区切ると0.7以上が出ることが分かりました。
for dataset in combine: dataset.loc[dataset['Age'] < 7, 'IsInfant'] = 1 dataset.loc[dataset['Age'] >= 7, 'IsInfant'] = 0 train_df_drpd['IsInfant'] = train_df_drpd['IsInfant'].astype(int) test_df_drpd['IsInfant'] = test_df_drpd['IsInfant'].astype(int) combine = [train_df_drpd, test_df_drpd]
そこで7歳未満を1とするフラグ型の特徴量'IsInfant'を作成。
t = train_df_drpd['Survived'].values x = train_df_drpd[['Sex', 'Pclass', 'IsInfant']].values x_test = test_df_drpd[['Sex', 'Pclass', 'IsInfant']].values rf.fit(x, t) pred_rf = rf.predict(x_test) rf.score(x, t)
Day3で出した最高スコアがRandom Forestで'Sex'と'Pclass'を使ったモデルだったので、それに'IsInfant'を学習させると、スコアは'0.8058361391694725'と悪くありません。強烈なスコアでもないので過学習にはなっていないように思います。
結果は、
 '0.77751'とベストスコアを更新。順位も3,745/14,205と上位26.4%と大躍進!前回から0.002くらいのスコアアップでこれくらい行くんですね。0.8を超えてくればメダルが見えてくるということかな(確認しろ自分)。
'0.77751'とベストスコアを更新。順位も3,745/14,205と上位26.4%と大躍進!前回から0.002くらいのスコアアップでこれくらい行くんですね。0.8を超えてくればメダルが見えてくるということかな(確認しろ自分)。
所感
やはり特徴量エンジニアリングにおいてビジュアライズは大事だなとひしひしと実感しました。あとは、家族系データ'SibSp', 'Parch'あたりから特徴量生成すればもっとスコア狙えそうです。楽しいです。
航海は続きます。