Kaggle / Titanic - Machine Learning from Disaster / 写経2 / @jun40vn / Day1
環境
Jupyter Lab / Local
新たに挑戦すること
表題のテーマについて自力でDay7で上位5.6%(Bronze Medal相当)に達したのですが、そこから上へいく、0.8以上を目指すことへのハードルがとてつもなく高かったので、自力から写経に戻ることにしました。
お手本は、こちら"KaggleチュートリアルTitanicで上位2%以内に入るノウハウ"です。
学んだこと
One Hot Encoding(ワンホットエンコーディング)
# ------------- 前処理 --------------- # 推定に使用する項目を指定 df = df[['Survived','Pclass','Sex','Age','Fare','Embarked','Title','Family_label','Cabin_label','Ticket_label']] # ラベル特徴量をワンホットエンコーディング df = pd.get_dummies(df) # データセットを trainとtestに分割 train = df[df['Survived'].notnull()] test = df[df['Survived'].isnull()].drop('Survived',axis=1) # データフレームをnumpyに変換 X = train.values[:,1:] y = train.values[:,0] test_x = test.values
`df = pd.get_dummies(df)'の部分のことです。
今まではEmbarkedについてS, Q, Cと3タイプあったカテゴリデータを0, 1, 2のように数値カテゴリ型に変換して1つの変数として扱っていました。が.get_dummies(df)を使うことでEmbarked_S, Embarked_Q, Embarked_Cという3変数に自動的に分解し、中身をBool(0/1)型に置き換えてくれます。
変換のための.map()等を使ったコーディングをする必要がないということもありますが、それ以上に後述するsklearn.feature_selectionからインポートできるライブラリ関数SelectKBest()を活用することで、EmbarkedのS, Q, CそれぞれをAIモデルに学習させるかどうかを個別に選択することができるようになるメリットが巨大でした。
モデリングにおけるSelectKBestの活用
# ----------- 推定モデル構築 --------------- from sklearn.feature_selection import SelectKBest from sklearn.ensemble import RandomForestClassifier from sklearn.pipeline import make_pipeline from sklearn.model_selection import cross_validate # 採用する特徴量を25個から20個に絞り込む select = SelectKBest(k = 20) clf = RandomForestClassifier(random_state = 10, warm_start = True, # 既にフィットしたモデルに学習を追加 n_estimators = 26, max_depth = 6, max_features = 'sqrt') pipeline = make_pipeline(select, clf) pipeline.fit(X, y)

k=20のところでモデル(今回はRandomForestの分類)に学習させる変数を20個に限定して、効果のあるものを選び出してくれます。この処理においてEmbarked_Qだけが学習データから除外されていることが分かります。先ほどのワンホットエンコーディングによる変数のBool型分解が効いています。
所感
この2つの処理については目鱗でした…。おかげで上位2%台に乗りましたが自力ではないので、今度は自力でここにたどり着けるか頑張ってみます。
航海は続きます。
Kaggle / Titanic - Machine Learning from Disaster / 独学 / とりあえず自分でやってみる Day6, 7
環境
Jupyter Lab / Local
今日やったこと
Day5でBest Scoreを更新して上位7.4%に入ったことに更に気をよくしてDay6は色々とやってみたが停滞。Day7では最初に現状のデータを、今まで生成してきた特徴量とともに眺めてみた。
Day5でのBest Scoreを叩き出したモデルの特徴量は'Sex', 'Pclass', 'TitleId', 'IsInfant'の4つ。性別、階級、家族的な要素が含まれたものになっていることに気づく。そして’Fare'については特徴量化していない。’Fare'も’Survived'と相関係数はまあまあ高いもののこれもモデルに入れると過学習が起こり、テストスコアが下がることも分かっている。
もう一度テーブルを眺めてみて、'Fare'を'FamiliSize(+1)'で割って'UnitFare'としてみたらどうだろうかと思いついた。
train_df_drpd['UnitFareBand'] = pd.cut(train_df_drpd['UnitFare'], 10) train_df_drpd[['UnitFareBand', 'Survived']].groupby(['UnitFareBand'], as_index=False).mean().sort_values(by='UnitFareBand', ascending=True)

pandasの.cut()の変数を色々と変えて'Survived'の平均値を見てみたところ、'UnitFare'<50あたりで生存率が35%前後と極めて低くなることが分かった。
要するに1人あたりのチケット金額が50を超えている人は生き残る確率が高いということかなと。
ということで’IsLowUnitPrice'という特徴量を生成。
for dataset in combine: dataset.loc[dataset['UnitFare'] < 50, 'IsLowUnitFare'] = 0 dataset.loc[dataset['UnitFare'] >= 50, 'IsLowUnitFare'] = 1 train_df_drpd['IsLowUnitFare'] = train_df_drpd['IsLowUnitFare'].astype(int) test_df_drpd['IsLowUnitFare'] = test_df_drpd['IsLowUnitFare'].astype(int) combine = [train_df_drpd, test_df_drpd]
Random Forestモデルに学習させてみたところ、モデルスコアは0.8114478114478114と、過学習も起こっていない悪くない数値(のような気がする)。結果…

submitスコア’0.79186'とベストを叩き出し、799 / 14,182で上位5.6%と更に高みへ。
所感
これが手探りで特徴量を作って手探りで組み合わせてモデルに学習している僕の今の限界かも…。
このあたりで独学を一度区切りとしてもう一度ネットの海から演繹的なお手本コードと解説を見ていこうかなと思います。
航海は続きます。
Kaggle / Titanic - Machine Learning from Disaster / 独学 / とりあえず自分でやってみる Day5
環境
Jupyter Lab / Local
今日やったこと
Day4で'IsInfant'と特徴量として加えることで上位26.4%に入ったのに気を良くして、'SibSp'と'Parch'を加算した'FamilySize'を生成。Survivedの平均値を算出。
for dataset in combine: dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] train_df_drpd[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=False).mean().sort_values(by='FamilySize', ascending=True)

自分以外に親族が1〜3人いる場合に生存率が約55〜72%となることに注目。その場合をに1をフラグとして建てる特徴量'IsSmallFamily'を生成。
for dataset in combine: dataset.loc[(dataset['FamilySize'] >= 1) & (dataset['FamilySize'] <= 3), 'IsSmallFamily'] = 1 dataset.loc[(dataset['FamilySize'] < 1) | (dataset['FamilySize'] >= 4), 'IsSmallFamily'] = 0 train_df_drpd['IsSmallFamily'] = train_df_drpd['IsSmallFamily'].astype(int) test_df_drpd['IsSmallFamily'] = test_df_drpd['IsSmallFamily'].astype(int) combine = [train_df_drpd, test_df_drpd]
Day4で良い結果を出した’Sex’, 'Pclass', 'IsInfant'に'IsSmallFamily'を加えてRandom Forestで学習。
t = train_df_drpd['Survived'].values x = train_df_drpd[['Sex', 'Pclass', 'IsInfant', 'IsSmallFamily']].values x_test = test_df_drpd[['Sex', 'Pclass', 'IsInfant', 'IsSmallFamily']].values rf.fit(x, t) pred_rf = rf.predict(x_test) rf.score(x, t)
モデルのスコアは'0.813692480359147'と悪くないものの、submitした結果は’0.77272’とDay4の結果に及ばず。
次に、'FamilySize'が0となる場合に1をフラグとして建てる特徴量'IsSingle'を生成。
for dataset in combine: dataset.loc[dataset['FamilySize'] == 0, 'IsSingle'] = 1 dataset.loc[dataset['FamilySize'] != 0, 'IsSingle'] = 0 train_df_drpd['IsSingle'] = train_df_drpd['IsSingle'].astype(int) test_df_drpd['IsSingle'] = test_df_drpd['IsSingle'].astype(int) combine = [train_df_drpd, test_df_drpd]
モデルのスコアは’0.8204264870931538’となるものの、submitした結果は’0.77272’と先ほどと全く同じ。
ここで基本に立ち返る意味で相関変数をもう一度見直してみる。
train_df_drpd_corr = train_df_drpd.corr()
print(train_df_drpd_corr)

submitしたスコアが良い特徴量である'Sex', 'Pclass', 'IsInfant'は目的変数'Survived'に対して良い相関係数が出ている。よく見ると’TitleId'も高い。そう言えば…この4つの特徴量で学習させていなかった、ことに気づく。
t = train_df_drpd['Survived'].values x = train_df_drpd[['Sex', 'Pclass', 'IsInfant', 'TitleId']].values x_test = test_df_drpd[['Sex', 'Pclass', 'IsInfant', 'TitleId']].values rf.fit(x, t) pred_rf = rf.predict(x_test) rf.score(x, t)
学習したモデルのスコアは'0.8080808080808081', これは過学習も効いていない感じの良い数値では?(感覚です…)

結果、submitスコア’0.78947'とベストスコアを叩き出し、1,038 / 14,269で上位7.2%を記録!!!
所感
アイヤー、こんな簡単なことだったのね…。
僕が組み合わせた特徴量は'IsInfant'だけなので、Day6では'FamilySize'の解読からの'Survived'に影響の強い特徴量を掴みに行きSubmitスコア0.8以上を狙おうと思います。
航海は続きます。
Kaggle / Titanic - Machine Learning from Disaster / 独学 / とりあえず自分でやってみる Day4
環境
Jupyter Lab / Local
今日やったこと
以前に下記の棒グラフを出力して眺めていた時に、
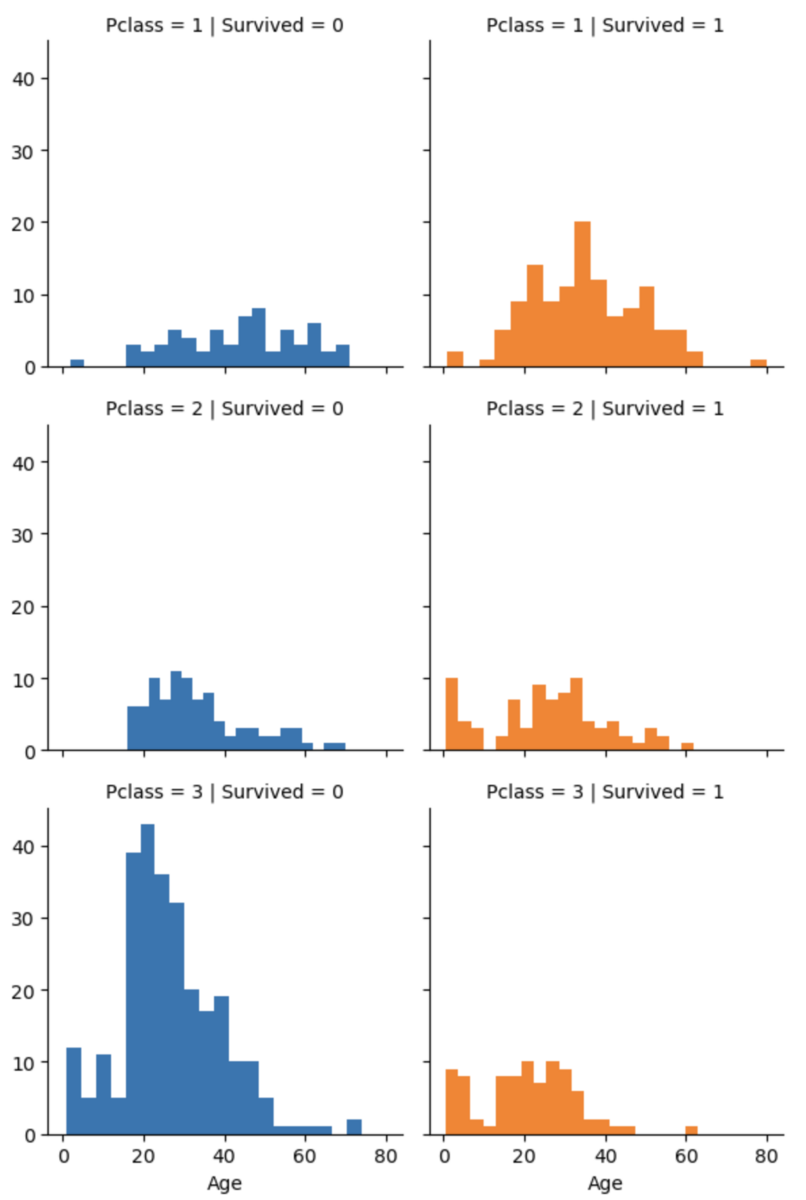 子どもの中でも特に幼児は生存率が極めて高いなと思っていました。'Pclass'が3, すなわち階級が低い層ではそんなことのない「北斗の拳」的世界観でしたが、それ以外では傾向が強いなと。まずは'Pclass'は置いておいて全体で幼児を切り分けて特徴量にしようと思いました。
子どもの中でも特に幼児は生存率が極めて高いなと思っていました。'Pclass'が3, すなわち階級が低い層ではそんなことのない「北斗の拳」的世界観でしたが、それ以外では傾向が強いなと。まずは'Pclass'は置いておいて全体で幼児を切り分けて特徴量にしようと思いました。
'Age'が連続数値型だったので'AgeBand'として年齢幅のカテゴリ化。
train_df_drpd['AgeBand'] = pd.cut(train_df_drpd['Age'], 12) train_df_drpd[['AgeBand', 'Survived']].groupby(['AgeBand'], as_index=False).mean().sort_values(by='AgeBand', ascending=True)
pandasの.cut()のパラメーターを色々と変えて
 'Survived'との相関係数が最も高くなる閾値を見ます。Jupyter LabなのでパラメーターいじってはShit+Enterの繰り返しで7歳未満で区切ると0.7以上が出ることが分かりました。
'Survived'との相関係数が最も高くなる閾値を見ます。Jupyter LabなのでパラメーターいじってはShit+Enterの繰り返しで7歳未満で区切ると0.7以上が出ることが分かりました。
for dataset in combine: dataset.loc[dataset['Age'] < 7, 'IsInfant'] = 1 dataset.loc[dataset['Age'] >= 7, 'IsInfant'] = 0 train_df_drpd['IsInfant'] = train_df_drpd['IsInfant'].astype(int) test_df_drpd['IsInfant'] = test_df_drpd['IsInfant'].astype(int) combine = [train_df_drpd, test_df_drpd]
そこで7歳未満を1とするフラグ型の特徴量'IsInfant'を作成。
t = train_df_drpd['Survived'].values x = train_df_drpd[['Sex', 'Pclass', 'IsInfant']].values x_test = test_df_drpd[['Sex', 'Pclass', 'IsInfant']].values rf.fit(x, t) pred_rf = rf.predict(x_test) rf.score(x, t)
Day3で出した最高スコアがRandom Forestで'Sex'と'Pclass'を使ったモデルだったので、それに'IsInfant'を学習させると、スコアは'0.8058361391694725'と悪くありません。強烈なスコアでもないので過学習にはなっていないように思います。
結果は、
 '0.77751'とベストスコアを更新。順位も3,745/14,205と上位26.4%と大躍進!前回から0.002くらいのスコアアップでこれくらい行くんですね。0.8を超えてくればメダルが見えてくるということかな(確認しろ自分)。
'0.77751'とベストスコアを更新。順位も3,745/14,205と上位26.4%と大躍進!前回から0.002くらいのスコアアップでこれくらい行くんですね。0.8を超えてくればメダルが見えてくるということかな(確認しろ自分)。
所感
やはり特徴量エンジニアリングにおいてビジュアライズは大事だなとひしひしと実感しました。あとは、家族系データ'SibSp', 'Parch'あたりから特徴量生成すればもっとスコア狙えそうです。楽しいです。
航海は続きます。
Kaggle / Titanic - Machine Learning from Disaster / 独学 / とりあえず自分でやってみる Day3
環境
Jupyter Lab / Local
今日やったこと
Day2で変数間の相関係数を調べたので、'Survived'に相関する変数'Sex', 'TitleId', 'Pclass', 'Fare'の4つについてRandom Forestでモデリングしてみてsubmitして結果を見てみた。
 結果、'Sex'と'Pclass'の2変数で0.77511と最高得点を更新。
結果、'Sex'と'Pclass'の2変数で0.77511と最高得点を更新。
所感
モデルのaccuracyスコア.score(x, t)では高得点が出てもテストデータではそうならないケースがあることに気づく。これは学習データに最適化されすぎているいわゆる過学習というやつですね。多分。
航海は続きます。
Kaggle / Titanic - Machine Learning from Disaster / 独学 / とりあえず自分でやってみる Day2
環境
Jupyter Lab / Local
今日やったこと
今日はほとんど進めていません、Errorと格闘してたりして…
年齢の欠損値について、性別と階級カテゴリーごとに中央値で補完。
### 'Age'と'Pclass'と'Sex'との間で相関関係がありそう→’Pclass'x'Sex'のmedian(), mean()で補完する # まず'Sex', 'Pclass'で行列を準備 guess_ages = np.zeros((2, 3)) # 行列'guess_ages'に'Sex', 'Pclass'における'Age'の中央値を代入 for dataset in combine: for i in range(0, 2): for j in range(0, 3): # 'Sex'がiで'Pclass'がj+1のレコードをDataFrameとして抽出 guess_df = dataset[(dataset['Sex'] == i) & (dataset['Pclass'] == j+1)]['Age'].dropna() # 中央値を算出 age_guess = guess_df.median() # 行列(i, j)に中央値を代入 guess_ages[i, j] = int(age_guess/0.5 + 0.5) * 0.5 # ここは分からない…職人技? for i in range(0, 2): for j in range(0, 3): dataset.loc[(dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1), 'Age'] = guess_ages[i, j] dataset['Age'] = dataset['Age'].astype(int)
テストデータにあった’Fare'の1つの欠損値を中央値で補完。
test_df_drpd['Fare'].fillna(test_df_drpd['Fare'].dropna().median(), inplace=True)
これで全データの欠損値を補完できました。
そこで、すべての変数について相関係数を出してみました。
train_df_drpd_corr = train_df_drpd.corr()
print(train_df_drpd_corr)
 こんな感じ。
こんな感じ。
それをseabornでheatmap化してみたりしました。

所感
null値の補完はこれで終わりました。中央値で補完していますが、平均値が良いのか良く分かりません。試行錯誤、経験によるものなのかな。
Kaggle / Titanic - Machine Learning from Disaster / 独学 / とりあえず自分でやってみる Day1
環境
Jupyter Lab / Local
写経の次に始めたこと
守破離じゃないですが、金メダリストの先生の写経から離れて、独自に精度を上げにいきます。そのために'train.csv'や'test.csv'をexcel先生で可視化して分析することなど、pythonに拘らずにやってみようと思っています(このくらいのレコード数ならSPSSの出番すらないですからね…)。
いきなりexcel先生の力を借りずにnull値の処理や、実は金メダリスト先生の写経ではやっていなかった外れ値の判定、処理などについてはpython上でやってしまおうかと思っています。
今日やったこと
データを可視化して、


'Sex', 'Embarked', 'Name'をint型のカテゴリに変換し、
null値が多い連続数値型の'Age'について'Pclass', 'Sex'と相関関係がありそうと判定し、

明日は'Pclass'と'Sex'の属性に基づいて平均値もしくは中央値で.fillna()補完するつもりです。
所感
もちろん独学で始めたとは言え、結局は金メダリスト先生のコードを見に行ったり、過去YouTube等で学習したコードを見たりはしています。
一方で先生を参照するまでは自分で考えてますので、試行錯誤、稚拙なコードを書いてエラーを出しながらやっているので、身についている感はあります。
さらに、こうして日記にしていくことで振り返り、抽象化・一般化して身体に落としていく感覚があります。
一歩一歩ですね。